NEWS
Introduction
As part of his master thesis supported by X41 Leonard Rapp analyzes the security of RustyHermit, a research unikernel developed at RWTH Aachen University. This blog post presents several security weaknesses found in RustyHermit up to at least commit hash 7014e15. The first blog post discussing missing memory protections in RustyHermit can be found here.
The basic idea of unikernels is to compile a library operating system together with an application into a singe purpose and single address space image which can be run on a hypervisor. This approach is much more lightweight in terms of code size, startup time and performance than a traditional operating system. RustyHermit is written in Rust and developed for high performance computing. It is still under development and not meant to be used in production.
Summary and Impact
It was found that RustyHermit lacks of heap protection mechanisms such as random allocation or pointer obfuscation. An attacker able to exploit a heap buffer overflow could use this to convert the simple linear heap buffer overflow to an arbitrary write, which can be easily used to gain code execution.
Also, the heap area is neither zeroed when allocating, nor when deallocating it. Thus, it is possible to read the content of a previously freed memory area when it gets allocated again. This might lead to the disclosure of sensitive information.
RustyHermit comes with its own rtl8139 network driver implementation, which has an out-of-bounds read vulnerability. An attacker exploiting this vulnerability would need to have control about the (emulated) network card firmware. Thus, the exploitability is very limited. Nevertheless, this is an interesting showcase that Rust does not solve all memory related security issues.
In addition, a bug was found in the tokenizer used to parse the starting command.
An attacker could use this bug to make the tokenizer parse parts of strings that are escaped by " or ' as not escaped and vice versa or to make the tokenizer ignore parts of the passed string.
As the tokenizer is only used to parse the boot command line string and its arguments, the impact is very limited.
An attacker controlling the boot command has full control over the unikernel anyways.
Detailed Analysis
The full analysis along with proof of concept code will be published as part of the master thesis in April 2022. Nevertheless, the core parts are presented in this blog post. While the first two findings presented are missing mitigations / security hardening features, the last two findings are (exploitable) bugs.
Missing Mitigation: Heap not Cleared Upon (De)allocation
The content of a heap area being freed is not cleared when freeing it neither when allocating it again. Thus, it is possible to read the content of a previously freed memory area when it gets allocated again. This might lead to the disclosure of sensitive information. A theoretical scenario could be an application handling user data. If one part of the memory is allocated for user A and filled with sensitive data and freed afterwards it might happen that the same memory area is allocated for user B afterwards, who might then be able to access A’s data.
With C on Linux, one can use calloc to allocate memory which is set to 0. Alternatively, on can set the M_PERTURB parameter to overwrite the memory when it gets allocated or freed. This takes effect when allocating memory areas above a certain size, probably due to performance considerations.
With Rust, there is no such mechanism for built-in structures.
Thus, it might be a beneficial additional security hardening to implement an optional kernel parameter for overwriting a heap area on allocation and / or free.
Missing Mitigation: No Hole Header Protection
For Rust applications, RustyHermit uses its own heap management.
The heap is implemented as a free list which is a linked list of so called holes.
Each hole has a header consisting of a size value describing the hole’s size and a next value which is a pointer to the next hole or to 0x0 if it is the last hole in the free list.
When memory on the heap is requested, the allocator goes through the linked list of holes and allocates the first hole that fits the requested size.
The size of an allocated area is always padded to a multiple of 128 byte.
pub struct Hole {
pub size: usize,
pub next: Option<&'static mut Hole>,
}
The hole header consisting of the size value and the next pointer is not protected by any kind of heap canary, integrity check or obfuscation.
Especially in combination with missing ASLR and a writable code segment this has the effect that a heap buffer overflow can be converted to an arbitrary write and might lead to code execution under certain circumstances.
A proof of concept exploit will be explained in detail in the following.
Let’s consider a scenario where an attacker is able to overflow Buffer 1, which is placed directly in front of a hole:
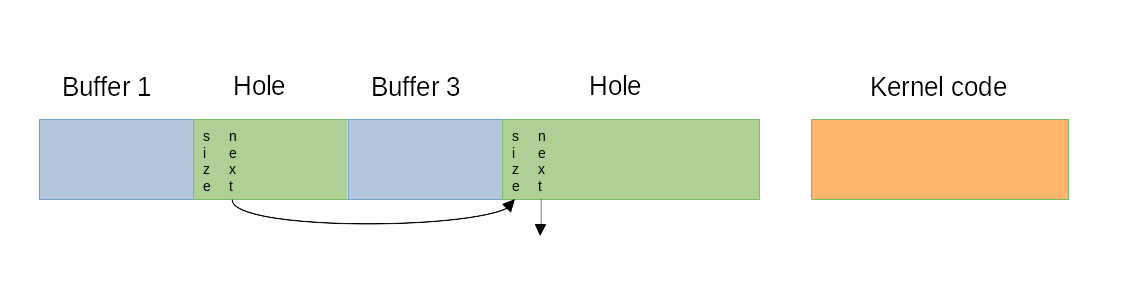
The attacker could now overflow the buffer and overwrite the hole’s header, letting the next pointer point to an arbitrary address, e.g. in the kernel code segment.
When the next allocation takes place, the allocator will follow the (manipulated) next pointer and will take whatever it points to as a hole. This is relatively foreseeable as the allocator linearly follows the linked list and uses a first fit method.
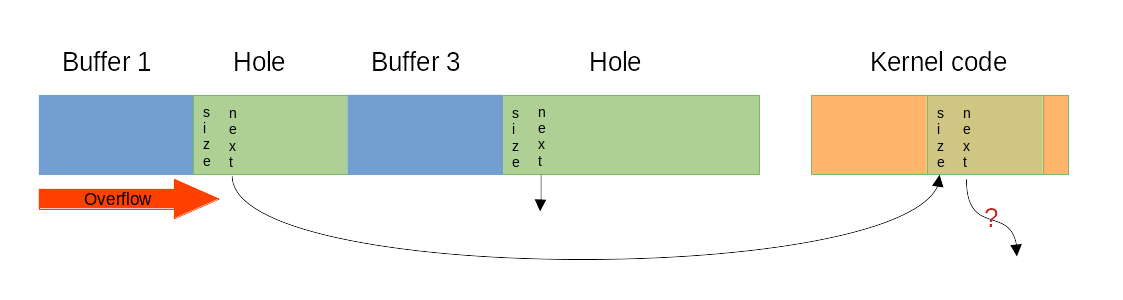
If the attacker also controls the second allocation’s content, this can be used to convert the original heap buffer overflow to an arbitrary write, which can be easily used to gain code execution (e.g. by overwriting kernel code due to the missing write protection).
However, this has some boundary conditions.
- The
sizevalue of the fake hole has to be larger than the one of all previous ones in the list, which is relatively likely when pointing to an arbitrary address. Also, the size of the requested allocation has to be larger than the size of all previous holes in the list, but smaller than the size of the fake hole in order to get exactly the fake hole allocated. - As the allocator follows the (fake) hole’s
nextpointer before allocating it, the pointer has to point to a readable address (or 0x0). Otherwise, this will lead to a page fault and crash the unikernel. - The double-free-check in the deallocator:
hole_addr + hole.size <= addr. Otherwise, the kernel will panic. If the second condition is met by letting thenextpointer point to0x0, the third condition is likely also met.
An attacker not able to meet those conditions can still use this as a denial of service attack.
Proof of concept code and the according output showing how to transform a heap buffer overflow into an arbitrary write can be found here.
Security Bug: rtl8139 Network Card Driver Out-of-bounds Read
The rtl8139 network card driver contains an out-of-bounds read vulnerability inside the receive_rx_buffer() function which parses the packet coming from the network card firmware.
The problem is that the length value read from the packet length field is blindly trusted without any further checks.
let length: u16 =
unsafe { *((self.rxbuffer.as_usize() + self.rxpos) as *const u16) } - 4; // copy packet (but not the CRC)
A corrupted (the CRC is never checked!) or actively manipulated length value would cause the function to return a slice which contains bytes that do not belong to the packet payload anymore. As the length is not restricted to the ring buffer size this does not only affect the other network packages inside the ring buffer, but also the bytes placed in the memory behind the ring buffer.
unsafe {
core::slice::from_raw_parts(
(self.rxbuffer.as_usize() + self.rxpos + mem::size_of::<u16>())
as *const u8,
length as usize,
)
},
In order to exploit the vulnerability, an attacker would have to control the package’s length field and thus the (emulated) rtl8139 on-chip firmware, which is relatively unlikely (if the attacker controls the host, we are lost anyway). Nevertheless, an exploit for this vulnerability could be chained with other potential exploits and should be fixed for an in-depth security approach. In addition, this shows that using Rust does not solve all memory related security issues.
Security Bug: Tokenizer Error Handling Broken
The tokenizer splits the input string into tokens at a given delimiter.
Parts of the input which are inside quote signs (" or ') are not split, but parsed as a single token.
When a quote sign appears in the input, the unquote function is called.
When an invalid escape char occurs inside the quoted part, the unquote function immediately returns an error and the tokenize function does ignore the part between (and including) the quote begin and the invalid escape char, thus this part gets dropped.
E.g. foo "bar\z" is tokenized as ["foo"].
As an additional effect, the quoted area is now “flipped”.
The tokenize function continues to parse the input at the point where the unquote function returned the error (which is inside the quoted area).
It splits at the delimiter, but should not do this.
When the tokenize function reaches the quote end sign, it interprets it as a quote begin sign and calls the unquote function again.
The unquote function will run into an error, as there is no end quote and show the same behavior as described above: Everything between the last (un)quote char and the end of the string will be dropped.
E.g. foo "bar\z baz biz" nope is tokenized as ["foo", "baz", "biz"]
As the tokenizer is only used to parse the boot command line string and its arguments, the impact is very limited.
An attacker controlling the boot command has full control over the unikernel anyways.
Disclosure
As RustyHermit is an ongoing research project which is not meant for use in production, it was agreed upon publicly documenting the security considerations in GitHub issues:
- libhermit-rs issue #373: Heap Areas not Zeroed when (De)allocated
- libhermit-rs issue #374: Missing Heap Hardening
- libhermit-rs issue #348: rtl8139 Network Card Driver Out-of-bounds Read
- libhermit-rs issue #346: Tokenizer: Code Confusing and Error Handling Broken
About X41 D-Sec GmbH
X41 is an expert provider for application security services. Having extensive industry experience and expertise in the area of information security, a strong core security team of world class security experts enables X41 to perform premium security services.
Fields of expertise in the area of application security are security centered code reviews, binary reverse engineering and vulnerability discovery. Custom research and IT security consulting and support services are core competencies of X41.